AWSのEC2インスタンスはホスト障害が起きるとAuto Recoveryと呼ばれる機能で自動的に復旧可能です。しかし、ホスト障害ではなくアプリケーション障害が起きた場合は、自動的に復旧する機能はないため、自力での実装が必要です。 ただ、これはAWSの機能を利用して実装できないものではありません。今回はプロセス監視を活用して自動復旧する方法をご説明します。
目次 <Contents>
AWSのアプリ障害は自動復旧への仕組み作りが必要
冒頭でも説明しましたが、EC2で起きたハードレベルでの障害はAuto RecoveryなどのAWSのサービスで復旧可能です。しかし、EC2上で動作するアプリケーションレベルでの障害は、AWSの標準サービスとしては問題が検知できないケースが多々あります。意外にも自力での仕組み作りが求められているのです。
AWSはシステム運用の自動化を推奨するパブリッククラウドサービスではあります。それは事実ですが、全てのサービスが提供されているわけではなく、ものによっては自力で実装しなければなりません。
AWSのアプリ障害を自動復旧するためのTips
アプリケーション障害はAWSのサービスでは自動的に復旧できないことをご理解いただけたでしょう。しかし、CloudWatchを活用すればプロセス監視を利用して、必要に応じて再起動などが可能になります。これを具体的に解説していきます。
CloudWatch Agentの導入
まずは、EC2での障害検知のために監視ツールの導入が必要です。AWSではCloudWatchを利用しますので、EC2にはCloudWatchを利用するための「CloudWatch Agent」をインストールしておきましょう。
CloudWatch Agentのパラメータ作成
具体的に監視する内容や、どのような動作をさせるかはCloudWatch Agentのパラメータとして作成します。そして、作成したものはパラメータストアに保存し、CloudWatchに読み込ませ動作するように設定します。
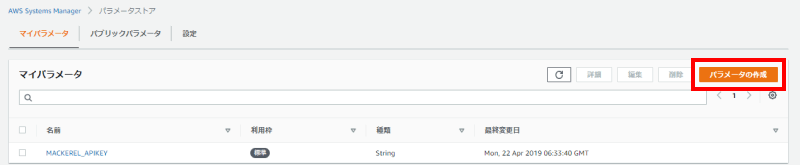
1パラメータストアを開き、「パラメータの作成」を押します。
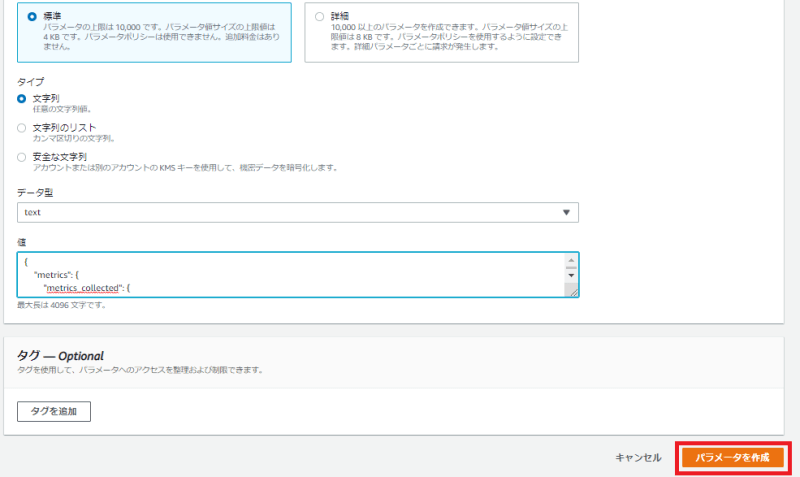
2パラメータの詳細設定画面が表示されますので、下記の通り設定します。
- 名前:必須・任意の文字列
- 説明:任意
- 利用枠:標準
- タイプ:文字列
続いて「値」と書かれているボックスに、下記の通りコードを入力します。
{
"metrics": {
"metrics_collected": {
"procstat": [
{
"exe": "sshd","measurement": ["pid_count"],"metrics_collection_interval": 180
}
]
}
}
}「”exe”:」に続いて監視したいプロセス名を記載します。今回は「sshd」を監視していますが、「httpd」など単独で存在するもの、Oracle導入時に生成される「ora」など複数存在するものを含め、プロセスとして存在するものであれば自由に変更が可能です。
入力が完了したら「パラメータの作成」を押し、パラメータを作成します。
CloudWatch Agentのパラメータ読み込み
上記の手順で作成したパラメータファイルをCloudWatch Agentへと読み込ませます。
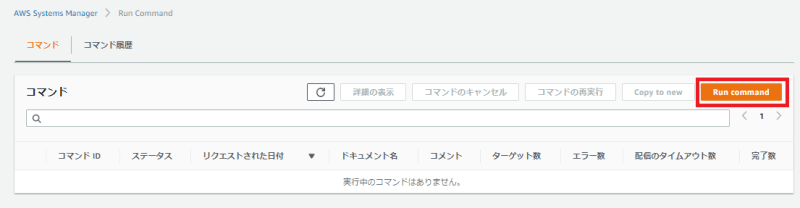
1「Run Command」画面を開き、「Run Command」ボタンを押します。
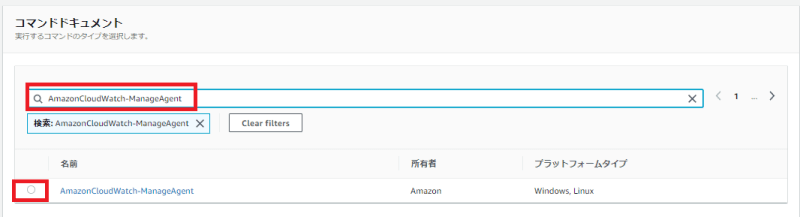
2「AmazonCloudWatch-ManageAgent」でフィルタリングをし、ラジオボタンにチェックを入れます。
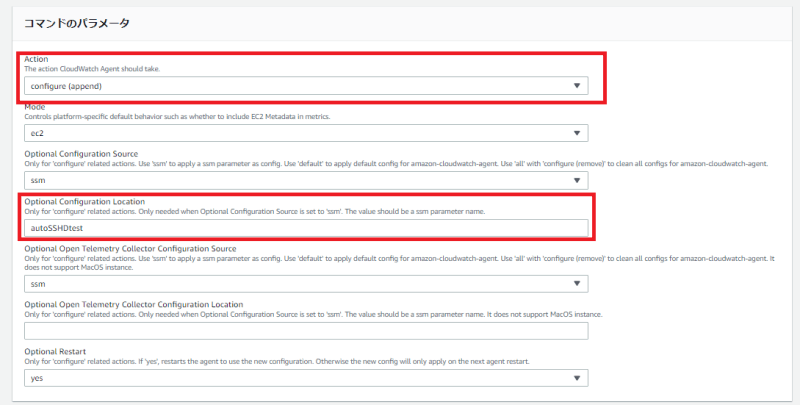
3画面下部にコマンドのパラメーターが表示されますので、以下のとおり設定します。
- Action:configure(appended)
- Optional Configuration Location:先程作成したパラメータ名
指定していない部分はデフォルトのまま変更しないようにします。4 のように設定されるはずです。
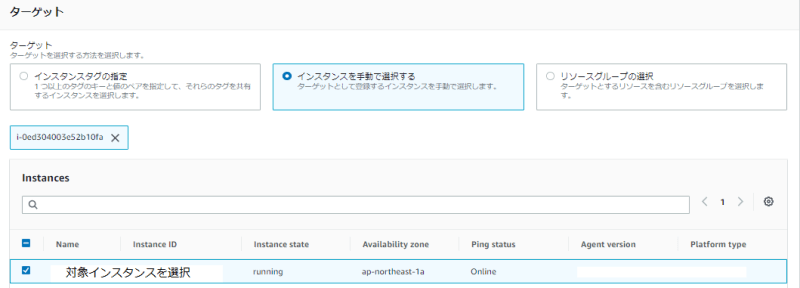
4問題なければ対象インスタンスを選択し、「実行」を押します。
CloudWatchの確認
設定作業が完了したら、メトリクスの確認方法を理解しておきましょう。
上記で設定した監視の内容は、CloudWatchの「メトリクス」内の「CWAgent > ImageId, InstanceId, InstanceType, exe, pid_finder」に収集されます。設定してすぐには反映されませんが、時間を置けば動作しますので、このタイミングでは表示されていなくとも気にする必要はありません。ここで対応する作業もありません。
CloudWatchで自動復旧の設定
メトリクスの設定準備ができれば、あとはCloudWatchでアラームを作成し、インスタンスの状態に応じて処理が動くように設定をするだけです。

1CloudWatchの「アラーム」画面を開き「アラームの作成」を押します。
「メトリクス」画面で「メトリクスの追加」を押し、先程の「CWAgent > ImageId, InstanceId, InstanceType, exe, pid_finder」を指定し、「メトリクスの選択」を押します。「メトリクスと条件の指定」画面が表示されますので、アラームの設定をします。
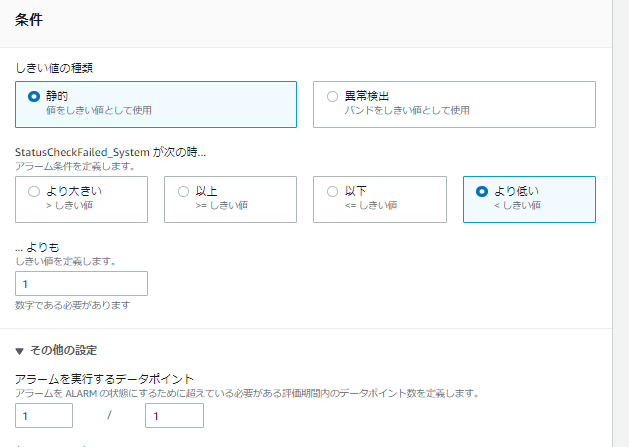
2設定が必要となるのはアラームの条件ですので、「条件」タブを以下のとおり設定します。
今回は「sshd」の監視ですので、監視対象となるプロセスは1つです。そのため、「プロセス数が1未満になった状態=プロセスが不足している状態」と判断するようにしています。監視する対象によっては、2つや3つのプロセスが同時に存在していることが「正常」と判断することになるでしょう。その時は正常と判断できるプロセス数をここに入力するようにしてください。適切に入力できれば画面下部の「次へ」を押します。
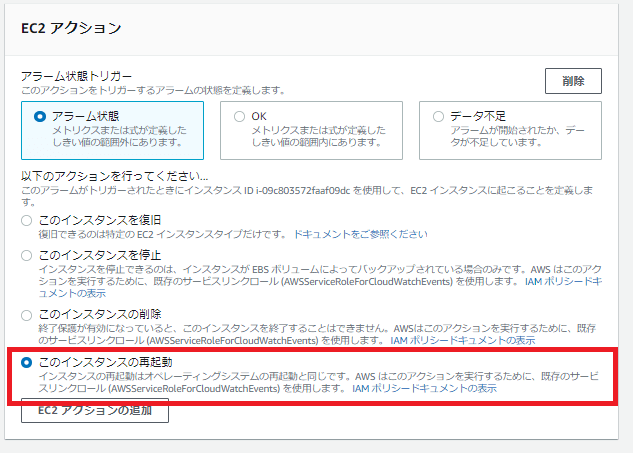
3「アクションの設定」画面が表示されますので、「EC2アクション」を設定します。
今回はアラーム状態となった場合に自動的に再起動し、プロセスの復旧を図る仕組みとしてみます。画像の通り、アラーム状態になった場合にインスタンスを再起動するように選択しましょう。
適切に選択できれば、画面下部の「次へ」を押します。
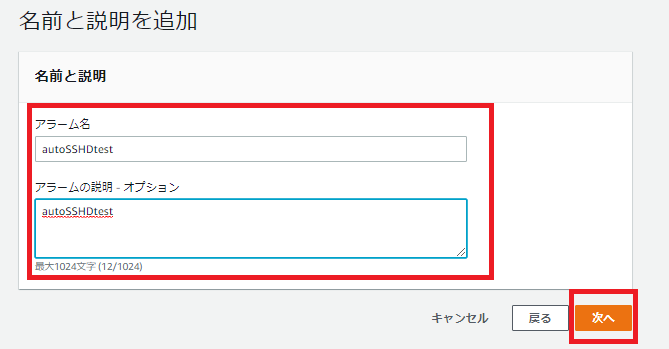
4「名前と説明を追加」画面が表示されますので、名称と説明を入力します。 入力が完了すれば「次へ」を押します。
5最後にプレビューが表示されますので、内容に問題がない確認し、画面下部の「次へ」を押して設定完了です。
まとめ
CloudWatchを利用してプロセスを監視し、閾値を下回った場合に自動的に再起動する仕組みを実現しました。システムにクリティカルな影響を与えるプロセスは、今回の手法で監視すると良いでしょう。
なお、今回はプロセスの異常をサーバーの以上とみなし自動的に再起動をしています。しかし、状況によってはプロセスだけ再起動したい場合もあるでしょう。その場合にはアラーム状態であることを「トピック」などに通知し、それをトリガーにプロセスのみを再起動するSSMやLambdaなどを起動してあげる仕組みとすれば良いのです。

 お客様が運営するクラウドの監視・保守・運用業務を、ジードが代行いたします。
お客様が運営するクラウドの監視・保守・運用業務を、ジードが代行いたします。 お客様のご要望に沿って、適切なクラウド選定から設計・構築までを行います。
お客様のご要望に沿って、適切なクラウド選定から設計・構築までを行います。 Azure上で、AI + 機械学習、分析、ブロックチェーン、IoTを開発します。
Azure上で、AI + 機械学習、分析、ブロックチェーン、IoTを開発します。